MapReduce 案例
WordCount 项目
Java 实现
- pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yjxxt</groupId>
<artifactId>hadoop-mr-wordcount-demo</artifactId>
<version>1.0</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- Hadoop版本控制 -->
<hadoop.version>3.1.2</hadoop.version>
<!-- commons-io版本控制 -->
<commons-io.version>2.4</commons-io.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>${commons-io.version}</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<!--工具包-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.4.1</version>
</dependency>
</dependencies>
<build>
<!-- <finalName>${project.name}</finalName>-->
<plugins>
<!--打包插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.5.5</version>
<configuration>
<archive>
<manifest>
<mainClass>com.yjxxt.job.WordCountJob</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<appendAssemblyId>false</appendAssemblyId>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 定义 Job 类
import cn.hutool.core.date.DatePattern;
import cn.hutool.core.date.DateUtil;
import com.yjxxt.mapper.WordCountMapper;
import com.yjxxt.reducer.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Date;
/**
* 统计单词次数的任务
*/
public class WordCountJob {
private static final int REDUCER_NUM = 2;
private static final String DATA_PATH = "/yjxxt/harry.txt";
public static void main(String[] args) throws Exception {
// 1. 加载配置
Configuration configuration=new Configuration(true);
// 本地运行
// 地运行的参数设置
//configuration.set("mapreduce.framework.name", "yarn");
// 2.创建Job类
Job job = Job.getInstance(configuration);
// 3. 设置Job相关参数
// 设置job的启动类
job.setJarByClass(WordCountJob.class);
String dateTimeStr = DateUtil.format(new Date(), DatePattern.PURE_DATETIME_FORMAT);
job.setJobName(String.format("wc_%s", dateTimeStr));
// 常量 --> 常量类 < 枚举 (配置文件)
job.setNumReduceTasks(REDUCER_NUM);
// 4. 设置数据读取与结果存储目录(HDFS上)
FileInputFormat.setInputPaths(job, new Path(DATA_PATH));
FileOutputFormat.setOutputPath(job,
new Path(String.format("/yjxxt/result/wc_%s", dateTimeStr)));
// Mapper输出的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 5. 指定Mapper 和 Reducer任务
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 6. 提交任务
job.waitForCompletion(true);
}
}
- 定义 Mapper 类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Arrays;
/**
* 统计单词的出现个数
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountMapper.class);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// None‘s good-ness them noticed a large, tawny owl flutter past the window.
LOGGER.info("输入偏移量key = {}, 读取的行value = {}", key, value);
String newValue = value.toString().replaceAll("[^a-zA-Z0-9'\\s]", "");
LOGGER.info("替换特殊字符Value = {}", newValue);
String[] strArrays = newValue.split(" ");
Arrays.stream(strArrays).forEach(v -> {
try {
context.write(new Text(v), new LongWritable(1));
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
- 定义 Reducer 类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountReducer.class);
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable,
Text, LongWritable>.Context context) throws IOException, InterruptedException {
long num = 0;
while(values.iterator().hasNext()) {
num += values.iterator().next().get();
}
LOGGER.info("输入的key = {}, value = {}", key, num);
// 输出
context.write(key, new LongWritable(num));
}
}
Resources 文件夹下放的配置文件
- core-site.xml
- hdfs-site.xml
- log4j.properties
- mapred-site.xml
- yarn-site.xml
Linux 上运行
使用插件 maven-assembly-plugin,打包好后将 jar 包上传到 linux 服务器,执行 hadoop jar wordcount.jar com.yjxxt.job.WordCountJob
天气信息
统计各地区每天的最高温和最低温
- 定义 WeatherJob 类
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Date;
/**
* 统计各区每天的最高和最低气温
*/
public class WeatherCounterJob {
public static void main(String[] args) throws Exception {
// 1. 创建配置文件
Configuration configuration = new Configuration(true);
configuration.set("mapreduce.framework.name", "local");
// 2. 创建job
String dateStr = DateUtil.format(new Date(), "yyyyMMddHHmmss");
String jobName = String.format("WeatherCounter-%s", dateStr);
Job weatherCounterJob = Job.getInstance(configuration, jobName);
// 关联job
weatherCounterJob.setJarByClass(WeatherCounterJob.class);
// 3. 配置job
weatherCounterJob.setMapOutputKeyClass(Text.class);
weatherCounterJob.setMapOutputValueClass(IntWritable.class);
// 4.设置数据输入输出路径
FileInputFormat.setInputPaths(weatherCounterJob,
"/yjxxt/data/area_weather.csv");
FileOutputFormat.setOutputPath(weatherCounterJob,
new Path(String.format("/yjxxt/result/%s", jobName)));
// 5.设置MapReduce任务
weatherCounterJob.setMapperClass(WeatherCounterMapper.class);
weatherCounterJob.setReducerClass(WeatherCounterReducer.class);
// 6. 提交job
weatherCounterJob.waitForCompletion(true);
}
}
- 定义 Maper 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WeatherCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 跳过第一行
if (key.get() == 0) {
return;
}
// "187","广东","南沙区","440115","雨","25","东北","≤3","96","1/6/2020 14:52:21","1/6/2020 15:00:03"
// 187,广东,南沙区,440115,雨,25,东北,≤3,96,1/6/2020 14:52:21,1/6/2020 15:00:03
String[] recode = value.toString().replaceAll("\"", "").split(",");
// "省市区:日期";
String outPutKey = String.format("%s%s%s:%s", recode[1],
recode[2], recode[3], recode[9].split(" ")[0]);
int temperature = Integer.parseInt(recode[5]);
context.write(new Text(outPutKey), new IntWritable(temperature));
}
}
- 定义 Reducer 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WeatherCounterReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//从key中获取最高和最低的气温
int minTemperature=Integer.MAX_VALUE;
int maxTemperature=Integer.MIN_VALUE;
while (values.iterator().hasNext()){
int temp=values.iterator().next().get();
//两个值取最小值
minTemperature=Math.min(temp, minTemperature);
//两个值取最大值
maxTemperature=Math.max(temp, maxTemperature);
}
Text outputValue=new Text(String.format("%s的最高温度是:%d, 最低温度是:%d", key, maxTemperature, minTemperature));
context.write(outputValue, null);
}
}
统计各地区每月的前三高温度
- 每个地区,每天的最高温度和最低温度分别是多少?
- 每个地区,每个月最高的三个温度以及它对应的是几号
代码实现
定义 Weather 类
import cn.hutool.core.date.DateUtil;
import com.google.common.base.Objects;
import lombok.*;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Date;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class WeatherWritable03 implements WritableComparable<WeatherWritable03> {
private String province;
private String city;
private String adcode;
private Date date; // 年月日,统一格式:yyyy-MM-dd
private int temperature;
private String winddirection;
private String windpower;
private String weather;
private String humidity;
@Override
public int compareTo(WeatherWritable03 o) {
// 省 > 市> 区> 日期 > 温度
int result = this.province.compareTo(o.province); // 从小到大
if (result == 0) {
result = this.city.compareTo(o.city);
if (result == 0) {
result = this.adcode.compareTo(o.adcode);
if (result == 0) {
result = DateUtil.format(this.date, "yyyy-MM").
compareTo(DateUtil.format(o.date, "yyyy-MM"));
if (result == 0) {
result = o.temperature - this.temperature;
}
}
}
}
return result;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
WeatherWritable03 that = (WeatherWritable03) o;
return temperature == that.temperature && Objects.equal(province, that.province)
&& Objects.equal(city, that.city) && Objects.equal(adcode, that.adcode)
&& Objects.equal(date, that.date) && Objects.equal(winddirection, that.winddirection)
&& Objects.equal(windpower, that.windpower) && Objects.equal(weather, that.weather)
&& Objects.equal(humidity, that.humidity);
}
@Override
public int hashCode() {
return Objects.hashCode(province, city, adcode, date, temperature, winddirection,
windpower, weather, humidity);
}
@Override
public String toString() {
return "WeatherWritable{" +
"province='" + province + '\'' +
", city='" + city + '\'' +
", adcode='" + adcode + '\'' +
", date='" + date + '\'' +
", temperature=" + temperature +
", winddirection='" + winddirection + '\'' +
", windpower='" + windpower + '\'' +
", weather='" + weather + '\'' +
", humidity='" + humidity + '\'' +
'}';
}
@Override
public void write(DataOutput out) throws IOException {
// 序列化数据
out.writeUTF(this.province);// 字符串
out.writeUTF(this.city);
out.writeUTF(this.adcode);
out.writeLong(this.date.getTime());
out.writeInt(this.temperature);
out.writeUTF(this.weather);
out.writeUTF(this.windpower);
out.writeUTF(this.winddirection);
out.writeUTF(this.humidity);
}
@Override
public void readFields(DataInput in) throws IOException {
// 反序列化
this.province = in.readUTF();
this.city = in.readUTF();
this.adcode = in.readUTF();
this.date = new Date(in.readLong());
this.temperature = in.readInt();
this.weather = in.readUTF();
this.windpower = in.readUTF();
this.winddirection = in.readUTF();
this.humidity = in.readUTF();
}
}
定义 WeatherGroupingComparator 分组比较器
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class WeatherGroupingComparator extends WritableComparator {
/**
* 必须写构造器
*/
public WeatherGroupingComparator() {
super(WeatherWritable03.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//将对象转型
WeatherWritable03 w1 = (WeatherWritable03) a;
WeatherWritable03 w2 = (WeatherWritable03) b;
//开始比较对象w1和w2(省 市 日期[年月])
int result = w1.getProvince().compareTo(w2.getProvince());
if (result == 0) {
//然后比较地区
result = w1.getCity().compareTo(w2.getCity());
if (result == 0) {
//然后比较日期
result = DateUtil.format(w1.getDate(), "yyyy-MM")
.compareTo(DateUtil.format(w2.getDate(), "yyyy-MM"));
//new SimpleDateFormat("yyyy-MM")
//.format(w1.getDate()).compareTo(new SimpleDateFormat("yyyy-MM")
// .format(w2.getDate()));
}
}
return result;
}
}
定义分区
import org.apache.hadoop.mapreduce.Partitioner;
public class WeatherWritablePartitioner extends Partitioner {
@Override
public int getPartition(Object o, Object o2, int numPartitions) {
return 0;
}
}
定义 Job 类
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Date;
/**
* 统计各区每月的气温
*/
public class WeatherCounterJob03 {
public static void main(String[] args) throws Exception {
// 1. 创建配置文件
Configuration configuration = new Configuration(true);
configuration.set("mapreduce.framework.name", "local");
// 2. 创建job
String dateStr = DateUtil.format(new Date(), "yyyyMMddHHmmss");
String jobName = String.format("WeatherCounter03-%s", dateStr);
Job weatherCounterJob = Job.getInstance(configuration, jobName);
// 关联job
weatherCounterJob.setJarByClass(WeatherCounterJob03.class);
// 3. 配置job
weatherCounterJob.setMapOutputKeyClass(WeatherWritable03.class);
weatherCounterJob.setMapOutputValueClass(IntWritable.class);
// 设置key的比较器
weatherCounterJob.setGroupingComparatorClass(WeatherGroupingComparator.class);
// weatherCounterJob.setPartitionerClass(WeatherWritablePartitioner.class);
// 4.设置输入输出
FileInputFormat.setInputPaths(weatherCounterJob, "/yjxxt/data/area_weather.csv");
FileOutputFormat.setOutputPath(weatherCounterJob, new Path(String.format("/yjxxt/result/%s", jobName)));
// 5.设置MapReduce任务
weatherCounterJob.setMapperClass(WeatherCounterMapper03.class);
weatherCounterJob.setReducerClass(WeatherCounterReducer03.class);
// 6. 提交job
weatherCounterJob.waitForCompletion(true);
}
}
定义 Mapper 类
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Date;
public class WeatherCounterMapper03 extends Mapper<LongWritable, Text, WeatherWritable03, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 跳过第一行
if (key.get() == 0) {
return;
}
// "187","广东","南沙区","440115","雨","25","东北","≤3","96","1/6/2020 14:52:21","1/6/2020 15:00:03"
// 187,广东,南沙区,440115,雨,25,东北,≤3,96,1/6/2020 14:52:21,1/6/2020 15:00:03
String[] recode = value.toString().replaceAll("\"", "").split(",");
// "省市区:日期";
String outPutKey = String.format("%s%s%s:%s", recode[1],
recode[2], recode[3], recode[9].split(" ")[0]);
int temperature = Integer.parseInt(recode[5]);
// 1/6/2020
// 11/6/2020
// 7/6/2020
// 2020-06-01
// 2020-06-07
// 2020-06-11
Date createTime = DateUtil.parse(recode[9], "dd/MM/yyyy HH:mm:ss"); // 日期时间对象01/06/2020 12:09:09
String yearAndMonthDateStr = DateUtil.format(DateUtil.date(DateUtil.calendar(createTime)), "yyyy-MM-dd"); // 2020-06-11 00:00:00 日期时间字符串
Date yearAndMonthDate = DateUtil.parse(yearAndMonthDateStr, "yyyy-MM-dd"); // 转成2020-06-11对象
// 通过建造者模式创建对象
WeatherWritable03 weatherWritable = WeatherWritable03.builder().weather(recode[4])
.adcode(recode[3]).city(recode[2])
.date(yearAndMonthDate)
.humidity(recode[8]).province(recode[1])
.temperature(temperature).winddirection(recode[6]).windpower(recode[7])
.build();
context.write(weatherWritable, new IntWritable(temperature));
}
}
定义 Reducer 类
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class WeatherCounterReducer03 extends Reducer<WeatherWritable03, IntWritable, Text, NullWritable> {
@Override
protected void reduce(WeatherWritable03 key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//容器
Set<String> set = new HashSet<>();
//获取迭代器
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
StringBuffer buffer = new StringBuffer();
buffer.append(key.getProvince()).append("|");
buffer.append(key.getCity()).append("|");
buffer.append(DateUtil.format(key.getDate(), "yyyy-MM-dd")).append("|");
buffer.append(iterator.next().get());
//存放到Set
set.add(buffer.toString());
//判断标准
if (set.size() == 3) {
break;
}
}
//写出结果
for (String s : set) {
context.write(new Text(s), null);
}
}
}
好友推荐系统
- 数据量
- QQ 好友推荐 -->
- 每个 QQ200 好友
- 5 亿 QQ 号
- QQ 好友推荐 -->
- 解决思路
- 需要按照行进行计算
- 将相同推荐设置成相同的 key,便于 reduce 统一处理
- 数据
tom hello hadoop cat world hello hadoop hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world hello hello tom world hive mr
好友推荐的代码实现
分析:
>例如张家辉的好友列表:张家辉 王海泉 钟添添 张雨 彭玉丹 谢丽萍 肖娴 夏新新 程琦慧 >--------------------------------------------------------------------------------------------------- >将这一行看作String数组,[张家辉,王海泉,钟添添,张雨,彭玉丹,谢丽萍,肖娴,夏新新,程琦慧] names[0]表示当前用户,names[i]表示他的好友;用数值表示推荐值 >直接好友:记直接好友为 0推荐值 >张家辉 王海泉 0 张家辉 钟添添 0 张家辉 张雨 0 ... >间接好友:记间接好友为1推荐值 >王海泉钟添添 1 王海泉 张雨 1 王海泉 彭玉丹 1 王海泉 谢丽萍 1 王海泉 肖娴 1 王海泉 夏新新 1 王海泉 程琦慧 1
定义一个 Friend 类
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Timestamp;
import java.util.Date;
import java.util.Objects;
/**
* 定义一个Friend类实现可写、数据库可写接口
*/
public class Friend implements Writable, DBWritable{
private String id;
private String person;//直接好友
private String friend;//间接好友
private Integer count;
private Date createtime;
public Friend() {
}
public Friend(String id, String person, String friend, Integer count, Date createtime) {
this.id = id;
this.person = person;
this.friend = friend;
this.count = count;
this.createtime = createtime;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getPerson() {
return person;
}
public void setPerson(String person) {
this.person = person;
}
public String getFriend() {
return friend;
}
public void setFriend(String friend) {
this.friend = friend;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public Date getCreatetime() {
return createtime;
}
public void setCreatetime(Date createtime) {
this.createtime = createtime;
}
@Override
public String toString() {
return "Friend{" +
"id='" + id + '\'' +
", person='" + person + '\'' +
", friend='" + friend + '\'' +
", count=" + count +
", createtime=" + createtime +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Friend friend1 = (Friend) o;
return Objects.equals(id, friend1.id) &&
Objects.equals(person, friend1.person) &&
Objects.equals(friend, friend1.friend) &&
Objects.equals(count, friend1.count) &&
Objects.equals(createtime, friend1.createtime);
}
@Override
public int hashCode() {
return Objects.hash(id, person, friend, count, createtime);
}
@Override
public void write(DataOutput dataOutput) throws IOException {
//将数据从内存序列化到磁盘上
dataOutput.writeUTF(this.id);
dataOutput.writeUTF(this.person);
dataOutput.writeUTF(this.friend);
dataOutput.writeInt(this.count);
dataOutput.writeLong(this.createtime.getTime());
}
@Override
public void readFields(DataInput dataInput) throws IOException {
//反序列化,从磁盘上读取数据
this.id = dataInput.readUTF();
this.person = dataInput.readUTF();
this.friend = dataInput.readUTF();
this.count = dataInput.readInt();
this.createtime = new Date(dataInput.readLong());
}
@Override
//序列化到数据库
public void write(PreparedStatement preparedStatement) throws SQLException {
preparedStatement.setString(1, this.id);
preparedStatement.setString(2, this.person);
preparedStatement.setString(3, this.friend);
preparedStatement.setInt(4, this.count);
preparedStatement.setTimestamp(5, new Timestamp(this.createtime.getTime()));
}
@Override
//从数据库中读取字段到内存中
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getString(1);
this.person = resultSet.getString(2);
this.friend = resultSet.getString(3);
this.count = resultSet.getInt(4);
this.createtime = resultSet.getTimestamp(5);
}
}
使用 reservoir Sampling 蓄水池算法随机生成好友
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.util.*;
import java.util.stream.Collectors;
/**
* 随机生成好友列表
*/
public class FriendRandomUtil {
public static void main(String[] args) throws IOException {
//读取学生信息
List<String> studentList = FileUtils.readLines(new File(FriendRandomUtil.class.getResource("/students.txt").getPath()));
//创建好友列表映射关系
Map<String, Set<String>> friendMap = studentList.stream().collect(Collectors.toMap(e -> e, e -> new HashSet<>()));
//开始计算
for (String student : friendMap.keySet()) {
//使用蓄水池算法获取随机好友
List<String> sampleList = FriendRandomUtil.reservoirSampling(studentList, new Random().nextInt(30) + 10);
//将数据添加到set
friendMap.get(student).addAll(sampleList);
//同时将当前学生添加到对方的好友
for (String friend : sampleList) {
friendMap.get(friend).add(student);
}
}
//打印好友信息
for (String student : friendMap.keySet()) {
System.out.print(student + "\t");
friendMap.get(student).stream().forEach(e -> System.out.print(e + "\t"));
System.out.println();
}
}
/**
* 蓄水池抽样算法
*
* @param studentList
* @param num
* @return
*/
public static List<String> reservoirSampling(List<String> studentList, int num) {
//定义数据的蓄水池
List<String> sampleList = studentList.subList(0, num);
//开始进行抽样
for (int i = num; i < studentList.size(); i++) {
//从0-j中随机出一个数
int r = new Random().nextInt(i);
if (r < num) {
//如果随机出的r<水池大小 ,则进行替换
sampleList.set(r, studentList.get(i));
}
}
return sampleList;
}
}
定义 FriendJob 任务类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendJob {
private static String driverClass = "com.mysql.cj.jdbc.Driver";
private static String url = "jdbc:mysql://192.168.191.101:3306/friend?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8";
private static String username = "root";
private static String password = "123456";
private static String tableName = "t_friends";
private static String[] fields = {"id", "person", "friend", "count", "createtime"};
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//加载配置
Configuration configuration = new Configuration(true);
configuration.set("mapreduce.framework.name", "local");
//加载数据库的配置文件
DBConfiguration.configureDB(configuration, driverClass, url
, username, password);
//创建Job类任务
Job job = Job.getInstance(configuration);
//设置Job参数
//设置job的启动类
job.setJarByClass(Hello01FriendJob.class);
//设置JonName,指定job的名称
job.setJobName("Hello01Friend" + System.currentTimeMillis());
//设置两个reduceTask任务
job.setNumReduceTasks(2);
//设置数据的输入路径
FileInputFormat.setInputPaths(job,new Path("/yjxxt/friends.txt"));
//设置要输出的结果路径
FileOutputFormat.setOutputPath(job, new Path("/yjxxt/result/friend_"+System.currentTimeMillis()));
//设置job输出格式类,指定到数据库
//job.setOutputFormatClass(DBOutputFormat.class);
//设置数据库输出格式,参数指定job任务和表名,字段
//DBOutputFormat.setOutput(job, tableName, fields);
//设置Map输出的key的类型为文本类型
job.setMapOutputKeyClass(Text.class);
//设置Map输出的Value的类型为可写的整型
job.setMapOutputValueClass(IntWritable.class);
//指定Mapper的执行类对象和Reducer的执行类对象
job.setMapperClass(FriendMap.class);
job.setReducerClass(FriendReducer.class);
//提交任务
job.waitForCompletion(true);
}
}
定义一个 FriendMap 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 张家辉 王海泉 钟添添 张雨 彭玉丹 谢丽萍 肖娴 夏新新 程琦慧
*
* 直接好友:记直接好友为 0推荐值
* 张家辉 王海泉 0 张家辉 钟添添 0 张家辉 张雨 0 ...
* 间接好友:记间接好友为1推荐值
* 王海泉 钟添添 1 王海泉 张雨 1 王海泉 彭玉丹 1 王海泉 谢丽萍 1 王海泉 肖娴 1 王海泉 夏新新 1 王海泉 程琦慧 1
*/
public class FriendMap extends Mapper<LongWritable, Text, Text, IntWritable> {
//声明静态成员变量
private static IntWritable one = new IntWritable(1);//静态变量1表示间接好友
private static IntWritable zero = new IntWritable(0);//0表示直接好友
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//切分数据,按照制表符对数据进行切割,然后存到一个names的字符串数组里
String[] names = value.toString().split("\t");
//开始拼接直接好友列表 names[0]-->当前用户
for (int i = 1; i < names.length; i++) {
//创建一个文本对象,按照名字进行排序,【当前用户names[0],直接好友为name[i]】
context.write(new Text(namesSort(names[0], names[i])), zero);
}
//开始拼接推荐好友列表
for (int i = 1; i < names.length; i++) {
for (int j = i + 1; j < names.length; j++) {// names[i] 和names[i+1]为间接好友
context.write(new Text(namesSort(names[i], names[j])), one);
}
}
}
/**
* 根据输入用户的名字进行排序
*
* @param name1
* @param name2
* @return
*/
private String namesSort(String name1, String name2) {
//根据用户名进行排序,name1大于name2 --> 将name1 放到name2前面,否则将name1放到name2后面
return name1.compareTo(name2) > 0 ? name2 + "-" + name1 : name1 + "-" + name2;
}
}
定义一个 FriendReducer 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Date;
import java.util.Iterator;
import java.util.UUID;
public class FriendReducer extends Reducer<Text, IntWritable, Friend, NullWritable> {
private String jobName;
//setup(Context context) **
protected void setup(Context context) throws IOException, InterruptedException {
jobName = context.getJobName();
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//声明累加器
int count = 0;
//从values获取迭代器
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
int value = iterator.next().get();
if (value == 0) {//value=0表示为直接好友,不再推荐给对方为好友
return;
}
count += value;
}
//开始写出数据,创建对象 何东-宋卿 11
String[] names = key.toString().split("-");//将key转换为String数组,然后按-分割[何东, 宋卿]
Friend f1 = new Friend(jobName + UUID.randomUUID().toString().substring(0, 9), names[0], names[1], count, new Date());
Friend f2 = new Friend(jobName + UUID.randomUUID().toString().substring(0, 9), names[1], names[0], count, new Date());
//写出数据
context.write(f1, NullWritable.get());
context.write(f2, NullWritable.get());
}
}
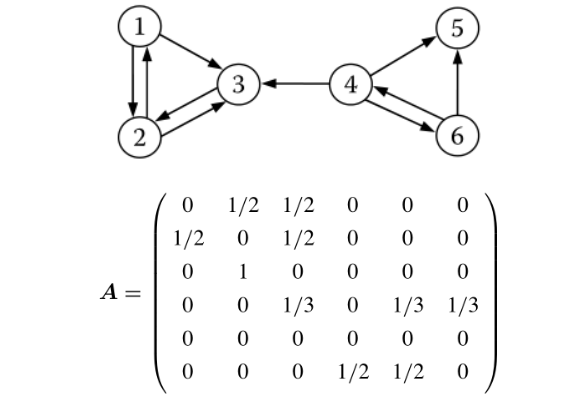
PageRank
基本概念
PageRank 是Sergey Brin 与 Larry Page 于 1998 年在 WWW7 会议上提出来的,用来解决链接分析中网页排名的问题
- PageRank 是 Google 提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度
- PageRank 实现了将链接价值概念作为排名因素
- 以后搜索对应关键词的时候,按照网站的权重顺序显示网页

方法的原理
投票算法
作为网络搜索引擎,他们会将全网的网站全部爬取到自己的服务器进行分析
然后分析出当前页面中到其他网站的外链(出链)
同时也有其他的网站链接到当前网站(入链)
入链的数量
如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要
-
入链的质量
质量高的页面会通过链接向其他页面传递更多的权重
算法过程
- 首先每个网站默认的权重是一样的(十分制,百分制)
- 然后将网站的权重平分给当前网站的所有出链 (10 / 5 = 2)
- 如果一个网站有多个入链,就将本次所有的入链得分累加到一起(2+4+7+1+10=24 分)
- 那么本次的得分会用于计算下次出链的计算 (24/5 = 4.8)
- 重复迭代上面的过程,慢慢达到一个收敛值
- 收敛标准是衡量本次计算精度的有效方法
- 超过 99.9% 的网站 pr 值和上次一样
- 所有的 pr 差值(本次和上次)累加求平均值不超过 0.0001
- 停止运算
阻尼系数
我自己申请 100 个域名,然后就指向自己的目标网站
- 闭环
- 只进不出
- 只出不进
修正 PageRank 计算公式:增加阻尼系数(damping factor)
- d=0.85
新的 PR 公式
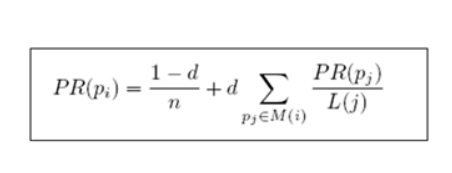
- d:阻尼系数 ---> 常量值 0.85
- M(i):指向 i 的页面集合 ---->对应入链页面集合
- L(j):页面的出链数 ---->对应出链页面集合-->代码中 String[] adjacentNodeNames 出链的数组
- PR(pj):j 页面的 PR 值 --> 常量值
- n:所有页面数 ---> 所有的页面
算法缺点
- 第一,没有区分站内导航链接。很多网站的首页都有很多对站内其他页面的链接,称为站内导航链接。这些链接与不同网站之间的链接相比,肯定是后者更能体现 PageRank 值的传递关系。
- 第二,没有过滤广告链接和功能链接。这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
- 第三,对新网页不友好。一个新网页的一般入链相对较少,即使它的内容的质量很高,要成为一个高 PR 值的页面仍需要很长时间的推广。
- 针对 PageRank 算法的缺点,有人提出了TrustRank 算法。其最初来自于 2004 年斯坦福大学和雅虎的一项联合研究,用来检测垃圾网站。TrustRank 算法的工作原理:先人工去识别高质量的页面 (即“种子” 页面),那么由 “种子” 页面指向的页面也可能是高质量页面,即其 TR 值也高,与 “种子” 页面的链接越远,页面的 TR 值越低。“种子”页面可选出链数较多的网页,也可选 PR 值较高的网站
- TrustRank 算法给出每个网页的 TR 值。将 PR 值与 TR 值结合起来,可以更准确地判断网页的重要性。
数据列举
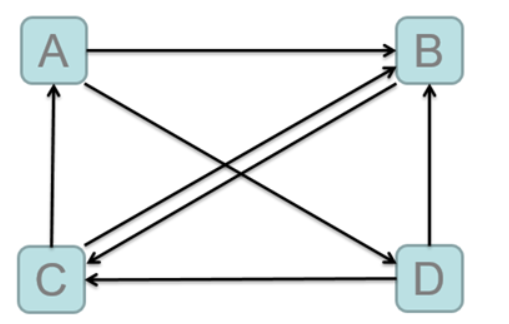
- ``` a b d b c c a b d b c
a 1.0 b d b 1.0 c c 1.0 a b d 1.0 b c
a 0.5 b d b 1.5 c c 1.5 a b d 0.5 b c
a 0. b d b 1.25 c c 1.75 a b d 0.25 b c
#### 执行流程分析:
a 1 b d b 1 c c 1 a b d 1 b c
开始进行拆分 --------> Map a 1 b d b 0.5 d 0.5 b 1 c c 1 c 1 a b a 0.5 b 0.5 d 1 b c b 0.5 c 0.5 --------->Reduce 第一次规约结果 a 0.5 b d b 1.5 c c 1.5 a b d 0.5 b c ---------------->Map 第二次.....

#### 分析
##### 1. 算法过程分析
- 首先每个网站默认的权重是一样的(十分制,百分制)假设默认初始值1.0
- 然后将网站的权重平分给当前网站的所有出链( 10 / 5 = 2 )
- 如果一个网站有多个入链,就将本次所有的入链得分累加到一起(2+4+7+1+10=24分)
- 那么本次的得分会用于计算下次出链的计算 (24/5 = 4.8)
- 重复迭代上面的过程,慢慢达到一个收敛值
##### 2. 逻辑分析
假设默认情况下,每个网站有1分的分值这些分值默认平分给所有的出链,等所有的网站将分数平分之后,开始计算本网站所有的入链分值;入链分值之和就是下次的网站的分数。
- 貔貅的问题 有些网站没有出链导致数据每次计算都在减少
+ 友情链接 防止自己的分数浪费,把 分值户给对方。
> 解决方案:
>
> 1. 添加阻尼系数来防止上面的问题 d = 0.85进行计算的最终结果会慢慢趋近与一个 收敛标准1.99%
>
> 2. 所有的网站的差值不超过 0.0001
##### 3. 加入阻尼系数后如何修正Pr值
修正PageRank计算公式:
+ 增加阻尼系数(damping factor)d=0.85
+ 新的PR公式
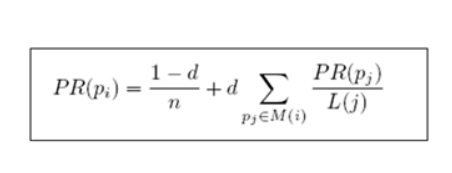
>- d:阻尼系数--->**常量值0.85**
>- M(i):指向i的页面集合---->**对应入链页面集合**
>- L(j):页面的出链数---->**对应出链页面集合**-->**代码中String[] adjacentNodeNames 出链的数组**
>- PR(pj):j页面的PR值-->每一轮的PR值经过计算都是确定的数值
>- n:所有页面数--->所有的页面
##### 4. 思路分析:
> 定义一个PageNode类,用于封装页面 PR和对应的出链地址;定义一个方法,根据传入的 pr值 + 出链字符串,将其转成Node对象。确定Map的key和value;判断是否为第一次加载,将数据封装成一个对象{pr,子连接};传递老的pr值和对应的页面关系
>
> 例如 a 0.75 b d 对应的出链和pr值
>
> key--> a value--> 0.75 b d ;明确了key和value后开始Map阶段拆分,判断节点对象是否含有出链,如果有就计算。开始计算每个节点本次应得的pr值;每个节点的pr=当前页面节点pr/出链的数量。Reducer阶段根据上面的公式进行计算,规约求出最终结果。在Job里判断是否达到收敛值,达到收敛标准就退出死循环。
#### 体代码实现
##### 定义一个枚举用于保存计算的收敛值
```java
public enum MyCounter {
//存放每次数据计算的收敛值之和
CONVERGENCESUM
}
定义一个 PageNode 类,用于封装页面 PR 和对应的出链地址
import org.apache.commons.lang.StringUtils;
import java.io.IOException;
import java.util.Arrays;
/**
* a 1.0 b d
* 封装页面 PR和对应的出链地址
* pageRank
* String[] adjacentNodeNames 出链的数组
*/
public class PageNode {
//页面权重值
private double pageRank = 1.0;
//出链的节点名字
private String[] adjacentNodeNames;
//分隔符
public static final char fieldSeparator = '\t';
/**
* 判断当前节点是否包含出链网站
*
* @return
*/
public boolean containsAdjacentNodes() {
return adjacentNodeNames != null && adjacentNodeNames.length > 0;
}
/**
* 根据传入的 pr + 出链字符串,将其转成Node对象
*
* @param value 0.3 B D
* @return
* @throws IOException
*/
public static PageNode fromMR(String value) throws IOException {
//按照分隔符切分数据
String[] parts = StringUtils.splitPreserveAllTokens(value, fieldSeparator);
//如果切分后小于一块,说明少了PR值和映射关系
if (parts.length < 1) {
throw new IOException("Expected 1 or more parts but received " + parts.length);
}
//创建节点对象
// Double.valueOf(parts[0])-->对应的是value值得0下标
// 例如:a 1.0 b d---》KeyValueTextInputFormat会将其分成两部分,第一列对应是key,后边的部分对应的是value
PageNode node = new PageNode().setPageRank(Double.valueOf(parts[0]));
//如果大于1说明有子节点,例如 a 1.0 parts数组长度不大于1说明只有节点和权重值没有出链
if (parts.length > 1) {
node.setAdjacentNodeNames(Arrays.copyOfRange(parts, 1, parts.length));
}
//返回节点
return node;
}
public static PageNode fromMR(String v1, String v2) throws IOException {
//a 1 b d
return fromMR(v1 + fieldSeparator + v2);
}
public double getPageRank() {
return pageRank;
}
public PageNode setPageRank(double pageRank) {
this.pageRank = pageRank;
return this;
}
public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
}
public PageNode setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(pageRank);
if (getAdjacentNodeNames() != null) {
sb.append(fieldSeparator).append(StringUtils.join(getAdjacentNodeNames(), fieldSeparator));
}
return sb.toString();
}
}
定义 PageRankJob 类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageRankJob {
//收敛的指标
private static double convergence = 0.0001;
public static void main(String[] args) {
//获取配置文件
Configuration configuration = new Configuration(true);
//跨平台执行
configuration.set("mapreduce.app-submission.cross-platform", "true");
configuration.set("mapreduce.framework.name", "local");
//计算迭代收敛的次数
int runCount = 0;
//开始执行迭代收敛
while (true) {
//计数累加
runCount++;
try {
//向配置文件中设置一个变量
configuration.setInt("runCount", runCount);
//获取分布式文件系统
FileSystem fs = FileSystem.get(configuration);
//创建JOB,并设置基本信息
Job job = Job.getInstance(configuration);
job.setJarByClass(PageRankJob.class);
job.setJobName("pagerank-" + runCount);
//设置Mapper的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Mapper和Reducer
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
//使用了新的输入格式化类
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置读取数据的路径(第一次)
Path inputPath = new Path("/yjxxt/pagerank/input/");
//第二次之后读取数据,就是前一次的结果
if (runCount > 1) {
inputPath = new Path("/yjxxt/pagerank/output/pr" + (runCount - 1));
}
//读取数据的路径
FileInputFormat.addInputPath(job, inputPath);
//本次输出路径
Path outpath = new Path("/yjxxt/pagerank/output/pr" + runCount);
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
//设置输出路径
FileOutputFormat.setOutputPath(job, outpath);
//提交任务,并获取本次任务是否成功
boolean flag = job.waitForCompletion(true);
if (flag) {
System.out.println("--------------------------success." + runCount);
//收敛值的和
long sum = job.getCounters().findCounter(MyCounter.CONVERGENCESUM).getValue();
double avgConvergence = sum / 40000.0;
//如果平均值达到收敛指标,停止循环
if (avgConvergence < convergence) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
定义一个 PageRankMapper 类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 第一次 a b d
* key a
* value b d
* 第二次 a 0.75 b d
* key a
* value 0.75 b d
*
* @author Administrator
*/
public class PageRankMapper extends Mapper<Text, Text, Text, Text> {
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
//如果是第一次读取文件,那么需要给PR设置默认值1
int runCount = context.getConfiguration().getInt("runCount", 1);
//以空格切分当前行,第一个空格前为KEY,其余数据为Value
String page = key.toString();
//定义对象Node
PageNode node = null;
//判断是否为第一次加载,将数据封装成一个对象{pr,子连接}
if (runCount == 1) {
node = PageNode.fromMR("1.0", value.toString());
} else {
node = PageNode.fromMR(value.toString());
}
//传递老的pr值和对应的页面关系 key--> a value--> 0.75 b d
context.write(new Text(page), new Text(node.toString()));
//开始计算每个节点本次应得的pr值
if (node.containsAdjacentNodes()) {
//每个节点的pr=当前页面节点pr/出链的数量
double outValue = node.getPageRank() / node.getAdjacentNodeNames().length;
//开始写出子节点和pr值
for (int i = 0; i < node.getAdjacentNodeNames().length; i++) {
String outPage = node.getAdjacentNodeNames()[i];
//页面A投给谁,谁作为key,val是票面值,票面值为:每个节点的pr
context.write(new Text(outPage), new Text(outValue + ""));
}
}
}
}
定义一个 PageRankReducer 类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Administrator
* //页面对应关系及老的pr值
* //a 1.0 b d
* //新的投票值
* //a 0.5
* //最终写出的结果
* //a 0.5 c
* //计算收敛差值 0.5-1.0= -0.5
*/
public class PageRankReducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> iterable, Context context) throws IOException, InterruptedException {
//定义变量存放新的PR值(阻尼之前)
double sum = 0.0;
//获取原来的节点
PageNode sourceNode = null;
for (Text i : iterable) {
//创建新的节点
PageNode node = PageNode.fromMR(i.toString());
//判断是老的映射关系还是新的PR值
if (node.containsAdjacentNodes()) {//老的包含出链
sourceNode = node;
} else {
sum = sum + node.getPageRank();//如果是新的就求出pr值
}
}
// 基于阻尼系数为重新计算PR值
double newPR = (0.15 / 4.0) + (0.85 * sum);
System.out.println(key + "*********** new pageRank value is " + newPR);
//把新的pr值和计算之前的pr比较(获取收敛值)
double d = newPR - sourceNode.getPageRank();//求出差值
//保留四位有效数字,然后取绝对值,j为收敛值
int j = Math.abs((int) (d * 1000.0));
context.getCounter(MyCounter.CONVERGENCESUM).increment(j);
//将当前网站的PR值写出
sourceNode.setPageRank(newPR);
context.write(key, new Text(sourceNode.toString()));
}
}
