数据库笔记
英文缩写概念
sql server 2008 数据库具有的三类文件 Mdf 主数据文件,Ndf 辅助数据文件,Ldf 日志文件
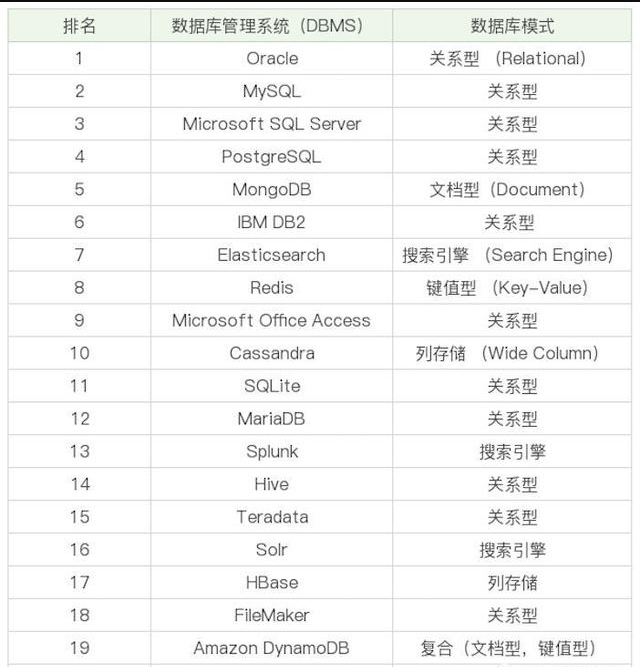
DBMS 是 “数据库管理系统” 的简称(全称 DataBase Management System)。实际上它可以对多个数据库进行管理,所以你可以理解为 DBMS = 多个数据库(DB) + 管理程序。所以大家可以想到虽然我们有时候把 Oracle、MySQL 等称之为数据库,但确切讲,它们应该是数据库管理系统,即 DBMS。
DB 是数据库的简称 (全称 DataBase)。数据库是存储数据的集合,你可以把它理解为多个数据表。
DBS 是数据库系统的简称 (全称 DataBase System)。它是更大的概念,包括了数据库、数据库管理系统以及数据库管理人员 DBA(DatabaseAdministrator)。
下面我们来看一下排名前 20 的 DBMS 都是那些?(2019 年 5 月 DB-Engines 公布的 DBMS 的排名)
数据模型(Data Model)是数据特征的抽象。数据(Data)是描述事物的符号记录,模型(Model) 是现实世界的抽象。数据模型从抽象层次上描述了系统的静态特征、动态行为和约束条件,为数据库系统的信息表示与操作提供了一个抽象的框架。数据模型所描述的内容有三部分:数据结构、数据操作和数据约束。
数据结构: 主要描述数据的类型、内容、性质以及数据间的联系等,是目标类型的集合。目标类型是数据库的组成成分,一般可分为两类:数据类型、数据类型之间的联系。数据类型如 DBTG(数据库任务组) 网状模型中的记录型、数据项,关系模型中的关系、域等。联系部分有 DBTG 网状模型中的系型等。数据结构是数据模型的基础,数据操作和约束都基本建立在数据结构上。不同的数据结构具有不同的操作和约束。
数据操作: 数据模型中数据操作主要描述在相应的数据结构上的操作类型和操作方式。它是操作算符的集合,包括若干操作和推理规则,用以对目标类型的有效实例所组成的数据库进行操作。
数据约束:数据模型中的数据约束主要描述数据结构内数据间的语法、词义联系、他们之间的制约和依存关系,以及数据动态变化的规则,以保证数据的正确、有效和相容。它是完整性规则的集合,用以限定符合数据模型的数据库状态,以及状态的变化。约束条件可以按不同的原则划分为数据值的约束和数据间联系的约束;静态约束和动态约束;实体约束和实体间的参照约束等。
关系模型
数据库主要有三种数据模型:
层次模型将数据组织成一对多关系的结构,层次结构采用关键字来访问其中每一层次的每一部分;
网状模型用连接指令或指针来确定数据间的显式连接关系,是具有多对多类型的数据组织方式;
关系模型以记录组或数据表的形式组织数据,以便于利用各种地理实体与属性之间的关系进行存储和变换,不分层也无指针,是建立空间数据和属性数据之间关系的一种非常有效的数据组织方法。
关系模式的定义
关系模式(Relation Schema)是对关系的描述, 它可以形式化地表示为:R(U,D,dom,F)。 其中 R 为关系名,U 为组成该关系的属性名集合,D 为属性组 U 中属性所来自的域,dom 为属性向域的映象集合,F 为属性间数据的依赖关系集合。
通常简记为:R(U)或R(A1,A2,…,An)其中R为关系名,U为属性名集合,A1,A2,…,An为各属性名。
有了定义,对关系模式有一个大概的认识(可以说基本上还是蒙的),那么按照实验的要求,我们要如何从 ER 图中的到一个关系模式呢?
ER 图转关系模式 这里我会以学生管理系统中常见的几个实体关系为例,设计简单你的 ER 图,并做转换说明。
1 对 1 转换关系 首先我们先从最简单的做起。这里我们将教师和课程的关系看做是 1:1 的关系(班主任), 然后 ER 图如下:

教师(性别,职工号,手机号,年龄,姓名)
班级(班级名称,班级号)
负责(职工号,班级号)
这就是一组关系模式,有人会说,负责这组关系模式好像多余呀。是的,下面我们就着手将其进行合并。
这里可以将教师和负责两个关系合并到一起,也可以选择将班级和负责合并到一起。
1. 合并教师和负责
教师(性别,职工号,手机号,年龄,姓名,班级号)
班级(班级名称,班级号)
合并就是将关系负责的属性添加到教师的属性中去,然后合并重复的属性。
2. 合并班级和负责
教师(性别,职工号,手机号,年龄,姓名)
班级(班级名称,班级号,职工号)
通过上面的合并,我们发现,合并后的两个关系才更像是我们最终的数据表结构。
1 对 n 转换关系 班级和学生是 1 对 n 的关系,ER 图如下:

同样的,我们有可以先得到一组独立地关系模式:
学生(学号,姓名,性别)
班级(班级名称,班级号)
包含(学号,班级号,人数)
然后将联系的关系进行合并。在 1 对 n 的关系中,需要将联系的关系添加到 n 的一方的关系模式中。
学生(学号,姓名,性别,班级号)
班级(班级名称,班级号)
m 对 n 转换关系 最后看一下多对多的关系是如何转换的。首先还是先给出 ER 图:

学生和课程的关系是 m:n 的。然后得到初步的关系模型:
学生(学号,姓名,性别)
课程(课程号,课程名)
选修(学号,课程号,成绩)
按照上面的惯例,下面我们应该合并关系模型了。但是在多对多的关系下,三种关系模式是不能进行合并的。而两个实体联系的关系模式正式我们常说的中间表的结构。
理解关系模式的作用 在上面通过 ER 图得到关系模式和合并关系模式的过程中,我们发现关系模式其实就是对应我们的数据表结构。那么关系模式有什么用呢,以往我们不通过关系模式一样可以得到表结构。
其实是没错的,但是通过范式的学习,发现我们的关系模式更多的时候是得到最终数据表的一个分析工具。就像我们上面一样,一开始会得到一个初始的独立的关系模式,然后对关系模式做合并,得到一个更加合理的关系模式。
使用范式也是一样的,我们会从基本的关系模式出发,然后利用范式的规则,得到最终更加合理的关系模式。这个过程如果只是靠抽象的想象的话,如果实体数量少还好说的,但是随着实体数越来越多,就会显得不大现实,而且准确性也会下降。
总的来说,通过对关系模式的化简合并,才会得到我们最终的实际编程用的数据表结构,比如下面这样:

基本操作分类
DML(data manipulation language):
它们是 SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这 4 条命令是用来对数据库里的数据进行操作的语言
数据的修改 众所周知的是,我们的项目中,有百分之八十的操作都是在查询,而仅有百分之二十的操作是做的数据修改。
所以,关系型数据库中对于数据的修改这块并没有什么很复杂的门道,我们优先介绍这一块内容,而对于数据的查询而言,它会复杂的多,各种排序、分组、子查询以及多表连接查询等等等等,就是旨在满足我们多样化的查询需求以及提升查询效率,这个我们稍后会介绍。
数据的修改包括,数据的插入、数据的修改以及数据的删除。
1、插入数据
向表中插入一条数据的 SQL 语法如下:
INSERT INTO [TABLE_NAME] (column1, column2, column3,...columnN)
VALUES (value1, value2, value3,...valueN);
那好,我们具体来看一个例子吧。
先创建这么一张 person 表,使用如下 SQL:
create table person(
id int primary key,
name varchar(16) not null,
age int,
phone varchar(11),
address varchar(256)
);
接着,我们插入一条数据:
insert into person(id,name,age,phone,address) values (1,'yang',22,'123232323',' 中国上海 '); 于是你查询 person 表,会看到
+----+------+------+-----------+--------------+
| id | name | age | phone | address |
+----+------+------+-----------+--------------+
| 1 | yang | 22 | 123232323 | 中国上海 |
+----+------+------+-----------+--------------+
当然,如果你在插入数据时有些字段的值暂时不想传入,或是该字段有默认值,insert 语句是允许你部分数据插入的,前提是不能违反一些非空、唯一、类型不匹配约束。
例如我只想插入一条数据,而我只知道这个人的名字,于是我也可以插入一条记录,但只赋值 name 字段。
insert into person(id,name)
values (2,'cao');
再次查询 person 表:
+----+------+------+-----------+--------------+
| id | name | age | phone | address |
+----+------+------+-----------+--------------+
| 1 | yang | 22 | 123232323 | 中国上海 |
| 2 | cao | NULL | NULL | NULL |
+----+------+------+-----------+--------------+
关系型数据库中,所有未赋值的字段都默认为 NULL,当然这个默认值是可以修改的,你可以修改为空字符串或空格等等。
再说一个细节,当你想要插入一条数据时,并且希望为该表的每一个字段都赋值,那么你可以不用在表名后列举所有字段名,例如以下两条 insert 语句是等效的。
insert into person(id,name,age,phone,address)
values (1,'yang',22,'123232323','中国上海');
insert into person
values (1,'yang',22,'123232323','中国上海');
关于 insert,我们暂时先说到这,后面介绍子查询的时候还会提到它,接着我们来看修改数据 update。
2、修改数据
SQL UPDATE 语句用于修改表中现有的记录。基本格式如下:
UPDATE [table_name]
SET column1 = value1, column2 = value2...., columnN = valueN
举个例子,这是 person 表现在的数据情况:
+----+------+------+-----------+--------------+
| id | name | age | phone | address |
+----+------+------+-----------+--------------+
| 1 | yang | 22 | 123232323 | 中国上海 |
| 2 | cao | NULL | NULL | NULL |
+----+------+------+-----------+--------------+
我们执行:
update person set address='浙江杭州'; 再来看 person 表:
+----+------+------+-----------+--------------+
| id | name | age | phone | address |
+----+------+------+-----------+--------------+
| 1 | yang | 22 | 123232323 | 浙江杭州 |
| 2 | cao | NULL | NULL | 浙江杭州 |
+----+------+------+-----------+--------------+
你会发现 person 表的所有记录的 address 字段全都修改为「浙江杭州」。
所以,一般来说,我们的 update 语句都会结合 where 子句做一个数据筛选,只修改符合条件的记录的 address 字段值。
例如:
update person set address='浙江杭州' where id = 1;
3、删除数据
我们使用 DELETE 语句对标数据进行删除,基本格式语法如下:
DELETE FROM [table_name]
WHERE [condition];
同样,不追加 where 子句做条件筛选会导致整张表的数据丢失。例如我们删除 id 为 1 的那条数据记录。
delete from person where id = 1;
数据的查询 SQL SELECT 语句用于从数据库的表中取回所需的数据,并以表的形式返回。返回的表被称作结果集。
基本的查询语法如下:
SELECT column1, column2, columnN FROM table_name;
如果需要查询一条记录中的所有的字段,可以用符号「*」替代全体,例如:
SELECT * FROM person;
可查询出 person 表所有的记录:
+----+-------+------+-----------+--------------+
| id | name | age | phone | address |
+----+-------+------+-----------+--------------+
| 1 | yang | 22 | 231232132 | 中国上海 |
| 2 | cao | NULL | NULL | 浙江杭州 |
| 3 | li | 23 | 34567894 | 江苏南京 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
+----+-------+------+-----------+--------------+ 这是最基本的查询,没有之一,接下来我们将一点点的增加复杂度,更熟练的掌握查询语句。
1、where 子句
where 子句又被称为条件子句,用于筛选查询出来的数据集,指定的条件语句中可以使用基本的算术、关系和逻辑运算,例如:>,<,=,!=,&&,||。
举个例子吧,person 表现在有如下数据:
+----+-------+------+------------+--------------+
| id | name | age | phone | address |
+----+-------+------+------------+--------------+
| 1 | yang | 22 | 231232132 | 中国上海 |
| 2 | cao | NULL | NULL | 浙江杭州 |
| 3 | li | 23 | 34567894 | 江苏南京 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
| 6 | yang | 24 | 2343435353 | 山东青岛 |
+----+-------+------+------------+--------------+
我们现需要查询出,名字叫「yang」,年龄为「22」的记录,该怎么写呢?
select * from person
where name='yang'&& age=22;
还是很简单的,虽然 where 子句很简单,但它却是我们 SQL 查询中最重要的一个关键字,基本上每一条 SQL 语句都离不开它。
在指定条件中,除了我们以上说的可以使用基本的逻辑算术运算符,子查询也是需要依赖 where 的,我们后面继续说。
2、LIKE 子句
LIKE 子句,我们一般用来做一些简单的搜索查询,或者说模糊匹配,表达式主要涉及到两个符号:
百分号 %:匹配任意多个字符 下划线 _:匹配固定一个字符 举几个例子吧,同样以我们的 person 表数据为例。
查询所有的数据,找到其中 name 字段以字符「ang」结尾的数据记录集合:
select * from person
where name like '%ang';
执行 SQL,返回结果:
+----+-------+------+------------+--------------+
| id | name | age | phone | address |
+----+-------+------+------------+--------------+
| 1 | yang | 22 | 231232132 | 中国上海 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
| 6 | yang | 24 | 2343435353 | 山东青岛 |
+----+-------+------+------------+--------------+
查询所有的数据,找到其中 name 字段以字符「ang」结尾,并且前面还有一个任意字符的数据记录集合:
select * from person
where name like '_ang';
执行 SQL,返回结果:
+----+------+------+------------+--------------+
| id | name | age | phone | address |
+----+------+------+------------+--------------+
| 1 | yang | 22 | 231232132 | 中国上海 |
| 6 | yang | 24 | 2343435353 | 山东青岛 |
+----+------+------+------------+--------------+
3、in 子句
in 关键字也是使用在 where 子句的条件表达式中,它限制的是一个集合,只要字段的值在集合中即符合条件,例如:
select * from person where age in (22,30,23); 这个 SQL 语句可以查询出来所有年龄是 22,30,23 的人数据记录。
你也可以使用 not in 反向限制,例如:
select * from person where age not in (22,30,23); 这个 SQL 则可以查出所有年龄不是这三个值的数据记录信息。
4、ORDER BY 子句
ORDER BY 子句根据一列或者多列的值,按照升序或者降序排列数据。某些数据库就默认以升序排列查询结果。
基本的 SQL 语法为:
SELECT column
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
ASC 表示数据结果集按升序排序,DESC 表示数据结果集按降序排序。
一般来说,我们按某一列进行排序即可,当然,有时候一列排序并不能完全解决问题,如果按多列排序,那么当遇到某一列值相同的时候,就会参照第二个列参数将这些重复列值得数据记录再一次排序。
举个例子:
我们将 person 表中的数据参照 id 列,倒序排序:
select * from person
order by id desc;
执行 SQL,查看结果:
+----+-------+------+------------+--------------+
| id | name | age | phone | address |
+----+-------+------+------------+--------------+
| 6 | yang | 24 | 2343435353 | 山东青岛 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 3 | li | 23 | 34567894 | 江苏南京 |
| 2 | cao | NULL | NULL | 浙江杭州 |
| 1 | yang | 22 | 231232132 | 中国上海 |
+----+-------+------+------------+--------------+
需要注意的是,对于数字类型的字段排序而言还相对容易理解些,对于非数字类型的排序,可能你不一定能看懂它为什么这样排序。
其实每个数据库都预定义了很多的排序规则,很多数据的实现都默认使用 utf8_general_ci 排序规则,当然,如果你很熟悉各种排序规则,你也可以在创建数据表的时候去主动指定使用哪种排序规则,一般使用默认排序规则就行。
5、GROUP BY 子句
GROUP BY 子句用于将查询返回的结果集进行一个分组,并展示各个分组中排在第一个的记录,将分组中其余成员隐藏。
我们为 person 表添加几条数据,用于演示:
+----+-------+------+------------+----------+
| id | name | age | phone | address |
+----+-------+------+------------+----------+
| 1 | yang | 22 | 231232132 | 中国上海 |
| 2 | cao | 30 | 456789 | 浙江杭州 |
| 3 | li | 23 | 34567894 | 江苏南京 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
| 6 | yang | 24 | 2343435353 | 山东青岛 |
| 7 | cao | 44 | 12312312 | 河南郑州 |
| 8 | huang | 45 | 5677675 | 安徽合肥 |
| 9 | yang | 80 | 3343738 | 江苏南通 |
+----+-------+------+------------+----------+
注意观察姓名列,有几组重复的姓名。
我们按照姓名对结果集进行分组,SQL 如下:
select * from person
group by name;
执行 SQL,得到结果:
+----+-------+------+-----------+----------+
| id | name | age | phone | address |
+----+-------+------+-----------+----------+
| 2 | cao | 30 | 456789 | 浙江杭州 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 3 | li | 23 | 34567894 | 江苏南京 |
| 1 | yang | 22 | 231232132 | 中国上海 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
+----+-------+------+-----------+----------+
你看,分组之后,只展示每个分组下排序第一的记录,其余成员隐藏。
细心的同学可能发现了,分组后的数据记录排序怎么乱了,怎么不是默认的 id 升序排列了?
对,如果你没有显式执行排序方式的话,将默认以你用于分组参照的那个字段进行排序。
当然,我们是可以执行排序方式的,使用 order by 子句:
select * from person
group by name
order by id;
效果是这样:
+----+-------+------+-----------+----------+
| id | name | age | phone | address |
+----+-------+------+-----------+----------+
| 1 | yang | 22 | 231232132 | 中国上海 |
| 2 | cao | 30 | 456789 | 浙江杭州 |
| 3 | li | 23 | 34567894 | 江苏南京 |
| 4 | huang | 33 | 34567894 | 湖北武汉 |
| 5 | zhang | 30 | 4567890 | 中国北京 |
+----+-------+------+-----------+----------+
这就是分组,可能会有同学疑问,这样的分组有什么意义,分组是分完了,给我返回每个分组的第一行记录有什么用?
其实是这样的,我们之所以进行分组,就是为了统计和估量每个分组下的指标情况,比如这组数据的平均年龄、最高薪水等等等等。
而当我们只是 「select *」的时候,数据库根本不知道你要干什么,换句话说就是你并没有对每一个分组中的数据进行任何的分析统计,于是给你返回该分组的第一行数据。
你要记住的是,每个分组只能出来一个数据行,究竟让什么样的数据出来取决于你。
比如我们计算每个分组下的平均年龄:
select avg(age) as '平均年龄' from person
group by name;
查询结果:
+----------+
| 平均年龄 |
+----------+
| 37.0000 |
| 39.0000 |
| 23.0000 |
| 42.0000 |
| 30.0000 |
+----------+
这里涉及了一个求平均数的函数 avg,我们后续会介绍这些常用函数,这里你体会下其意思就行。
6、HAVING 子句
HAVING 子句在我看来就是一个高配版的 where 子句,无论是我们的分组或是排序,都是基于以返回的结果集,也就是说 where 子句的筛选已经结束。
那么如果我们对排序、分组后的数据集依然有筛选需求,就用到我们的 HAVING 子句了。
例如:
select avg(age) as vage from person
group by name
having vage>23;
分组之后,我们得到每个分组中数据的平均年龄,再者我们通过 having 语句筛选出平均年龄大于 23 的数据记录。
以上我们介绍了六个子句的应用场景及其使用语法,但是如果需要同时用到这些子句,语法格式是什么样的?作用优先级是什么样的?
SELECT column1, column2
FROM table
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
大家一定要记住这个模板,各个子句在 SQL
语句中的位置,可以不出现,但不得越位,否则就会报语法错误。
首先是 from 语句,查出表的所有数据,接着是 select
取指定字段的数据列,然后是 where 进行条件筛选,得到一个结果集。
接着 group by 分组该结果集并得到分组后的数据集,having 再一次条件筛选,最后才轮到 order by 排序。
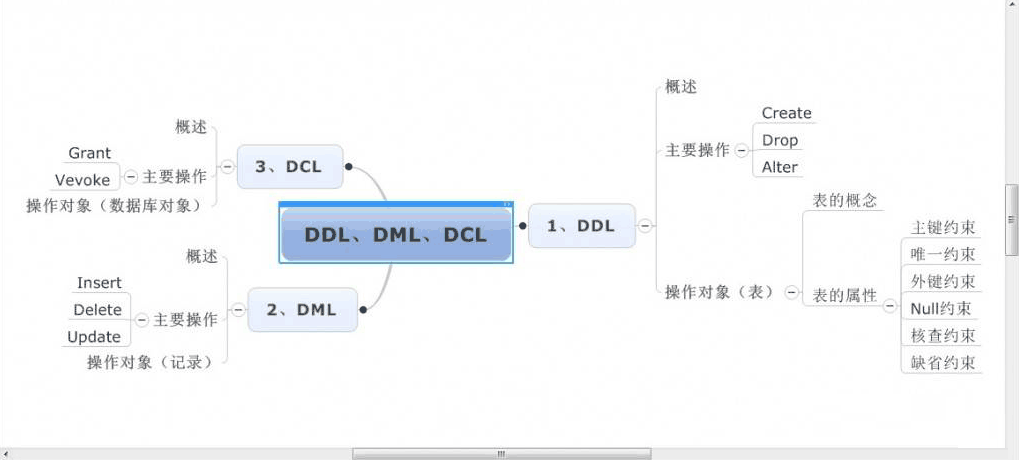
DDL(data definition language):
DDL 比 DML 要多,主要的命令有 CREATE、ALTER、DROP 等,DDL 主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
create database 创建数据库
create database stuDB
on primary -- 默认就属于baiprimary文件组,可省略
(
/*--数据文件的具体描述du--*/
name='stuDB_data', -- 主数据文件的逻辑名称
filename='D:\stuDB_data.mdf', -- 主数据文件的物理名称
size=5mb, --主数据文件的初始大小
maxsize=100mb, -- 主数据文件增长的最大值
filegrowth=15%--主数据文件的增长率
)
log on
(
/*--日志文件的具体描述,各参数含义同上,亦可省略--*/
name='stuDB_log',
filename='D:\stuDB_log.ldf',
size=2mb,
filegrowth=1mb
)
create table 创建表
CREATE TABLE 语句 CREATE TABLE 语句用于创建数据库中的表。
SQL CREATE TABLE 语法
CREATE TABLE 表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
....
)
数据类型(data_type)规定了列可容纳何种数据类型。下面的表格包含了 SQL 中最常用的数据类型:
数据类型 描述
integer(size)
int(size)
smallint(size)
tinyint(size)
仅容纳整数。在括号内规定数字的最大位数。
decimal(size,d)
numeric(size,d)
容纳带有小数的数字。
"size" 规定数字的最大位数。"d" 规定小数点右侧的最大位数。
char(size) 容纳固定长度的字符串(可容纳字母、数字以及特殊字符)。
在括号中规定字符串的长度。
varchar(size) 容纳可变长度的字符串(可容纳字母、数字以及特殊的字符)。
在括号中规定字符串的最大长度。
date(yyyymmdd) 容纳日期。 SQL CREATE TABLE 实例 本例演示如何创建名为 "Person" 的表。
该表包含 5 个列,列名分别是:"Id_P"、"LastName"、"FirstName"、"Address" 以及 "City":
CREATE TABLE Persons
(
Id_P int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
alert table 修改表
ALTER TABLE 语句 ALTER TABLE 语句用于在已有的表中添加、修改或删除列。
SQL ALTER TABLE 语法 如需在表中添加列,请使用下列语法:
ALTER TABLE table_name
ADD column_name datatype
要删除表中的列,请使用下列语法:
ALTER TABLE table_name
DROP COLUMN column_name
注释:某些数据库系统不允许这种在数据库表中删除列的方式 (DROP COLUMN column_name)。
要改变表中列的数据类型,请使用下列语法:
ALTER TABLE table_name
ALTER COLUMN column_name datatype
原始的表 (用在例子中的): Persons 表:
Id LastName FirstName Address City
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
SQL ALTER TABLE 实例
现在,我们希望在表 "Persons" 中添加一个名为 "Birthday" 的新列。
我们使用下列 SQL 语句:
ALTER TABLE Persons
ADD Birthday date
请注意,新列 "Birthday" 的类型是 date,可以存放日期。数据类型规定列中可以存放的数据的类型。
新的 "Persons" 表类似这样:
Id LastName FirstName Address City Birthday
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
改变数据类型实例 现在我们希望改变 "Persons" 表中 "Birthday" 列的数据类型。
我们使用下列 SQL 语句:
ALTER TABLE Persons
ALTER COLUMN Birthday year
请注意,"Birthday" 列的数据类型是 year,可以存放 2 位或 4 位格式的年份。
Drop table or database
SQL DROP INDEX 语句 我们可以使用 DROP INDEX 命令删除表格中的索引。
用于 Microsoft SQLJet (以及 Microsoft Access) 的语法:
DROP INDEX index_name ON table_name
用于 MS SQL Server 的语法:
DROP INDEX table_name.index_name
用于 IBM DB2 和 Oracle 语法:
DROP INDEX index_name
用于 MySQL 的语法:
ALTER TABLE table_name DROP INDEX index_name
SQL DROP TABLE 语句
DROP TABLE 语句用于删除表(表的结构、属性以及索引也会被删除):
DROP TABLE 表名称 SQL DROP DATABASE 语句 DROP DATABASE 语句用于删除数据库:
DROP DATABASE 数据库名称 SQL TRUNCATE TABLE 语句 如果我们仅仅需要除去表内的数据,但并不删除表本身,那么我们该如何做呢?
请使用 TRUNCATE TABLE 命令(仅仅删除表格中的数据):
TRUNCATE TABLE 表名称
create view 创建、更新、删除视图
SQL CREATE VIEW 语句 什么是视图? 在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
注释:数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。
SQL CREATE VIEW 语法
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
注释:视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
SQL CREATE VIEW 实例 可以从某个查询内部、某个存储过程内部,或者从另一个视图内部来使用视图。通过向视图添加函数、join 等等,我们可以向用户精确地提交我们希望提交的数据。
样本数据库 Northwind 拥有一些被默认安装的视图。视图 "Current Product List" 会从 Products 表列出所有正在使用的产品。这个视图使用下列 SQL 创建:
CREATE VIEW [Current Product List] AS
SELECT ProductID,ProductName
FROM Products
WHERE Discontinued=No
我们可以查询上面这个视图:
SELECT * FROM [Current Product List]
Northwind 样本数据库的另一个视图会选取 Products 表中所有单位价格高于平均单位价格的产品:
CREATE VIEW [Products Above Average Price] AS
SELECT ProductName,UnitPrice
FROM Products
WHERE UnitPrice>(SELECT AVG(UnitPrice) FROM Products)
我们可以像这样查询上面这个视图:
SELECT * FROM [Products Above Average Price] 另一个来自 Northwind 数据库的视图实例会计算在 1997 年每个种类的销售总数。请注意,这个视图会从另一个名为 "Product Sales for 1997" 的视图那里选取数据:
CREATE VIEW [Category Sales For 1997] AS
SELECT DISTINCT CategoryName,Sum(ProductSales) AS CategorySales
FROM [Product Sales for 1997]
GROUP BY CategoryName
我们可以像这样查询上面这个视图:
SELECT * FROM [Category Sales For 1997]
我们也可以向查询添加条件。现在,我们仅仅需要查看 "Beverages" 类的全部销量:
SELECT * FROM [Category Sales For 1997]
WHERE CategoryName='Beverages'
SQL 更新视图
您可以使用下面的语法来更新视图:
SQL CREATE OR REPLACE VIEW Syntax
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
现在,我们希望向 "Current Product List" 视图添加 "Category" 列。我们将通过下列 SQL 更新视图:
CREATE VIEW [Current Product List] AS
SELECT ProductID,ProductName,Category
FROM Products
WHERE Discontinued=No
SQL 撤销视图
您可以通过 DROP VIEW 命令来删除视图。
SQL DROP VIEW Syntax
DROP VIEW view_name
DCL(Data Control Language):
是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke 等)语句。在默认状态下,只有 sysadmin,dbcreator,db_owner 或 db_securityadmin 等人员才有权力执行 DCL
数据库授权与收权
1. 授权命令 grant, 语法格式 (SQL 语句不区分大小写):
Grant <权限> on 表名 [(列名)] to 用户 With grant option 如果不加 with grant option 该用户将无权将权限授予其他人 或 GRANT <权限> ON <数据对象> FROM <数据库用户>
// 数据对象可以是表名或列名
// 权限表示对表的操作,如 select,update,insert,delete
2. 回收权限 revoke
REVOKE <权限> ON <数据对象> FROM <数据库用户名> 如果咱写完了的话 权限:
select:查看数据库表数据权限
insert:插入数据库表数据权限
update:修改数据库表数据权限
delete:删除数据库表数据权限
create:创建数据库表权限
alter:修改数据库表属性权限
drop:删除数据库表权限
references:操作数据库表外键权限
create temporary:操作MySQL数据库临时表权限
index:操作MySQL索引权限
create view:操作MySQL视图权限
show view:查看MySQL视图属性权限
create routine:
alter routine:
execute:
all privileges:普通DBA管理员权限
all:高级DBA管理员权限
TCL - Transaction Control Language:
事务控制语言,COMMIT - 保存已完成的工作,SAVEPOINT - 在事务中设置保存点,可以回滚到此处,ROLLBACK - 回滚,SET TRANSACTION - 改变事务选项
BEGIN TRANSACTION
标记一个显式本地事务的起始点。 BEGIN TRANSACTION 使 @@TRANCOUNT 按 1 递增。
BEGIN TRANSACTION 代表一点,由连接引用的数据在该点逻辑和物理上都一致的。 如果遇上错误,在 BEGIN TRANSACTION 之后的所有数据改动都能进行回滚,以将数据返回到已知的一致状态。 每个事务继续执行直到它无误地完成并且用 COMMIT TRANSACTION 对数据库作永久的改动,或者遇上错误并且用 ROLLBACK TRANSACTION 语句擦除所有改动。
BEGIN TRANSACTION 为发出本语句的连接启动一个本地事务。 根据当前事务隔离级别的设置,为支持该连接所发出的 Transact-SQL 语句而获取的许多资源被该事务锁定,直到使用 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 语句完成该事务为止。 长时间处于未完成状态的事务会阻止其他用户访问这些锁定的资源,也会阻止日志截断。
虽然 BEGIN TRANSACTION 启动一个本地事务,但是在应用程序接下来执行一个必须记录的操作(如执行 INSERT、UPDATE 或 DELETE 语句)之前,它并不被记录在事务日志中。 应用程序能执行一些操作,例如为了保护 SELECT 语句的事务隔离级别而获取锁,但是直到应用程序执行一个修改操作后日志中才有记录。
语法
BEGIN {TRAN | TRANSACTION}
[ { transaction_name | @tran_name_variable }
[ WITH MARK [ 'description' ] ]
]
[;]
参数
transaction_name
分配给事务的名称。 transaction_name 必须符合标识符规则,但标识符所包含的字符数不能大于 32。 仅在最外面的 BEGIN...COMMIT 或 BEGIN...ROLLBACK 嵌套语句对中使用事务名。 transaction_name 始终是区分大小写的,即使 SQL Server 实例不区分大小写也是如此。
@tran_name_variable
用户定义的、含有有效事务名称的变量的名称。 必须用 char、varchar、nchar 或 nvarchar 数据类型声明变量。 如果传递给该变量的字符多于 32 个,则仅使用前面的 32 个字符;其余的字符将被截断。
WITH MARK ['description']
指定在日志中标记事务。 description 是描述该标记的字符串。 长于 128 个字符的 description 先截断为 128 个字符,然后才存储到 msdb.dbo.logmarkhistory 表中。
如果使用了 WITH MARK,则必须指定事务名。 WITH MARK 允许将事务日志还原到命名标记。
COMMIT TRANSACTION
标志一个成功的隐性事务或显式事务的结束。仅当事务引用的所有数据在逻辑上都正确时,才应发出 COMMIT TRANSACTION 命令。 如果 @@TRANCOUNT 为 1,COMMIT TRANSACTION 使得自从事务开始以来所执行的所有数据修改成为数据库的永久部分,释放事务所占用的资源,并将 @@TRANCOUNT 减少到 0。如果 @@TRANCOUNT 大于 1,则 COMMIT TRANSACTION 使 @@TRANCOUNT 按 1 递减并且事务将保持活动状态。
如果所提交的事务是 Transact-SQL 分布式事务,COMMIT TRANSACTION 将触发 MS DTC 使用两阶段提交协议,以便提交所有涉及该事务的服务器。 如果本地事务跨越同一数据库引擎实例上的两个或多个数据库,则该实例将使用内部的两阶段提交来提交所有涉及该事务的数据库。当 @@TRANCOUNT 为 0 时发出 COMMIT TRANSACTION 将会导致出现错误;因为没有相应的 BEGIN TRANSACTION。
不能在发出一个 COMMIT TRANSACTION 语句之后回滚事务,因为数据修改已经成为数据库的一个永久部分。
仅当事务计数在语句开始处为 0 时,数据库引擎才会增加语句内的事务计数。
语法
COMMIT [{TRAN | TRANSACTION} [transaction_name | @tran_name_variable] ] [WITH ( DELAYED_DURABILITY = { OFF | ON} ) ]
[;]
参数
transaction_name
SQL Server 数据库引擎忽略此参数。 transaction_name 指定由前面的 BEGIN TRANSACTION 分配的事务名称。 transaction_name 必须符合标识符规则,但不能超过 32 个字符。 transaction_name 通过向程序员指明 COMMIT TRANSACTION 与哪些 BEGIN TRANSACTION 相关联,可作为帮助阅读的一种方法。
@tran_name_variable
用户定义的、含有有效事务名称的变量的名称。 必须用 char、varchar、nchar 或 nvarchar 数据类型声明变量。 如果传递给该变量的字符数超过 32,则只使用 32 个字符,其余的字符将被截断。
DELAYED_DURABILITY
请求将此事务与延迟持续性一起提交的选项。 如果已用 DELAYED_DURABILITY = DISABLED 或 DELAYED_DURABILITY = FORCED 更改了数据库,则忽略该请求。
ROLLBACK TRANSACTION 将显式事务或隐性事务回滚到事务的起点或事务内的某个保存点。 可以使用 ROLLBACK TRANSACTION 清除自事务的起点或到某个保存点所做的所有数据修改。 它还释放由事务控制的资源。ROLLBACK TRANSACTION 语句不生成显示给用户的消息。 如果在存储过程或触发器中需要警告,请使用 RAISERROR 或 PRINT 语句。 RAISERROR 是用于指出错误的首选语句。
语法
ROLLBACK {TRAN | TRANSACTION}
[ transaction_name | @tran_name_variable
| savepoint_name | @savepoint_variable ]
[;]
参数
transaction_name
是为 BEGIN TRANSACTION 上的事务分配的名称。 transaction_name 必须符合标识符规则,但只使用事务名称的前 32 个字符。 嵌套事务时,transaction_name 必须是最外面的 BEGIN TRANSACTION 语句中的名称。 transaction_name 始终是区分大小写的,即使 SQL Server 实例不区分大小写也是如此。
@ tran_name_variable
用户定义的、含有有效事务名称的变量的名称。 必须用 char、varchar、nchar 或 nvarchar 数据类型声明变量。
savepoint_name
是 SAVE TRANSACTION 语句中的 savepoint_name。 savepoint_name 必须符合有关标识符的规则。 当条件回滚应只影响事务的一部分时,可使用 savepoint_name。
@ savepoint_variable
是用户定义的、包含有效保存点名称的变量的名称。 必须用 char、varchar、nchar 或 nvarchar 数据类型声明变量。
SAVE TRANSACTION
在事务内设置保存点。保存点可以定义在按条件取消某个事务的一部分后,该事务可以返回的一个位置。 如果将事务回滚到保存点,则根据需要必须完成其他剩余的 Transact-SQL 语句和 COMMIT TRANSACTION 语句,或者必须通过将事务回滚到起始点完全取消事务。 若要取消整个事务,请使用 ROLLBACK TRANSACTION transaction_name 语句。 这将撤消事务的所有语句和过程。在事务中允许有重复的保存点名称,但指定保存点名称的 ROLLBACK TRANSACTION 语句只将事务回滚到使用该名称的最近的 SAVE TRANSACTION。
语法
SAVE {TRAN | TRANSACTION} {savepoint_name | @savepoint_variable}
[;]
参数
savepoint_name
分配给保存点的名称。 保存点名称必须符合标识符的规则,但长度不能超过 32 个字符。 transaction_name 始终是区分大小写的,即使 SQL Server 实例不区分大小写也是如此。
@savepoint_variable
包含有效保存点名称的用户定义变量的名称。 必须用 char、varchar、nchar 或 nvarchar 数据类型声明变量。 如果长度超过 32 个字符,也可以传递到变量,但只使用前 32 个字符。
示例 以下示例说明如果活动事务是在执行存储过程之前启动的,如何使用事务保存点仅回滚存储过程所做的修改。
复制代码 USE AdventureWorks2012;
GO
IF EXISTS (SELECT name FROM sys.objects
WHERE name = N'SaveTranExample')
DROP PROCEDURE SaveTranExample;
GO
CREATE PROCEDURE SaveTranExample
@InputCandidateID INT
AS
-- 检查是否是在活动的事务里面调用该存储过程(嵌套事务)
-- @TranCounter = 0 表示不是在活动事务里面调用
-- @TranCounter > 0 表示在该存储过程调用之前已经有一个活动的事务
DECLARE @TranCounter INT;
SET @TranCounter = @@TRANCOUNT;
IF @TranCounter > 0
-- 在该存储过程调用之前已经有一个活动的事务。创建一个保存点,如果这个存储过程出错,只回滚到执行存储过程之前的操作。
SAVE TRANSACTION ProcedureSave;
ELSE
-- 创建一个新的事务
BEGIN TRANSACTION;
-- Modify database.
BEGIN TRY
DELETE HumanResources.JobCandidate
WHERE JobCandidateID = @InputCandidateID;
.
IF @TranCounter = 0
-- @TranCounter = 0 只在这个存储过程里面有事务,必须提交事务
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- 错误发生,需要去判断回滚级别
IF @TranCounter = 0
-- 事务只在此存储过程中,回滚整个事务
-- Roll back complete transaction.
ROLLBACK TRANSACTION;
ELSE
-- 事务在此存储过程开始之前已经创建(嵌套事务)
-- XACT_STATE(),用于报告当前正在运行的请求的用户事务状态的标量函数。 XACT_STATE 指示请求是否有活动的用户事务,以及是否能够提交该事务。
-- XACT_STATE() = 1 ,当前请求有活动的用户事务。 请求可以执行任何操作,包括写入数据和提交事务。
-- XACT_STATE() = 0,当前请求没有活动的用户事务。
-- XACT_STATE() = -1 ,当前请求具有活动的用户事务,但出现了致使事务被归类为无法提交的事务的错误。 请求无法提交事务或回滚到保存点;它只能请求完全回滚事务。
-- 请求在回滚事务之前无法执行任何写操作。 请求在回滚事务之前只能执行读操作。 事务回滚之后,请求便可执行读写操作并可开始新的事务。
IF XACT_STATE() <> -1
-- 回滚到此存储过程开始之前的错作。
ROLLBACK TRANSACTION ProcedureSave;
-- 输出错误信息
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT @ErrorMessage = ERROR_MESSAGE();
SELECT @ErrorSeverity = ERROR_SEVERITY();
SELECT @ErrorState = ERROR_STATE();
RAISERROR (@ErrorMessage,
@ErrorSeverity,
@ErrorState
);
END CATCH
存储过程
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的 SQL 语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数 (需要时) 来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用 SELECT 指令来运行,因为它是子程序,与查看表,数据表或用户定义函数不同。
- 存储过程可以用在数据检验,强制实行商业逻辑等。
缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同。当切换到其他厂商的数据库系统时,需要重写原有的存储过程。
- 存储过程的性能调校与撰写,受限于各种数据库系统。
一、存储过程的创建和调用 存储过程就是具有名字的一段代码,用来完成一个特定的功能。 创建的存储过程保存在数据库的数据字典中。 创建存储过程
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
routine_body:
Valid SQL routine statement
[begin_label:] BEGIN
[statement_list]
……
END [end_label]
MYSQL 存储过程中的关键语法
声明语句结束符,可以自定义:
DELIMITER $$
或
DELIMITER //
声明存储过程:
CREATE PROCEDURE demo_in_parameter(IN p_in int)
存储过程开始和结束符号:
BEGIN .... END
变量赋值:
SET @p_in=1
变量定义:
DECLARE l_int int unsigned default 4000000;
创建 mysql 存储过程、存储函数:
create procedure 存储过程名(参数)
存储过程体:
create function 存储函数名(参数)
实例 创建数据库,备份数据表用于示例操作:
mysql> create database db1;
mysql> use db1;
mysql> create table PLAYERS as select * from TENNIS.PLAYERS;
mysql> create table MATCHES as select * from TENNIS.MATCHES;
下面是存储过程的例子,删除给定球员参加的所有比赛:
mysql> delimiter $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
mysql> CREATE PROCEDURE delete_matches(IN p_playerno INTEGER)
-> BEGIN
-> DELETE FROM MATCHES
-> WHERE playerno = p_playerno;
-> END$$
Query OK, 0 rows affected (0.01 sec)
mysql> delimiter; #将语句的结束符号恢复为分号
解析:默认情况下,存储过程和默认数据库相关联,如果想指定存储过程创建在某个特定的数据库下,那么在过程名前面加数据库名做前缀。 在定义过程时,使用 DELIMITER $$ 命令将语句的结束符号从分号 ; 临时改为两个 $$,使得过程体中使用的分号被直接传递到服务器,而不会被客户端(如 mysql)解释。
调用存储过程:
call sp_name[(传参)];
mysql> select * from MATCHES;
+---------+--------+----------+-----+------+
| MATCHNO | TEAMNO | PLAYERNO | WON | LOST |
+---------+--------+----------+-----+------+
| 1 | 1 | 6 | 3 | 1 |
| 7 | 1 | 57 | 3 | 0 |
| 8 | 1 | 8 | 0 | 3 |
| 9 | 2 | 27 | 3 | 2 |
| 11 | 2 | 112 | 2 | 3 |
+---------+--------+----------+-----+------+
5 rows in set (0.00 sec)
mysql> call delete_matches(57);
Query OK, 1 row affected (0.03 sec)
mysql> select * from MATCHES;
+---------+--------+----------+-----+------+
| MATCHNO | TEAMNO | PLAYERNO | WON | LOST |
+---------+--------+----------+-----+------+
| 1 | 1 | 6 | 3 | 1 |
| 8 | 1 | 8 | 0 | 3 |
| 9 | 2 | 27 | 3 | 2 |
| 11 | 2 | 112 | 2 | 3 |
+---------+--------+----------+-----+------+
4 rows in set (0.00 sec)
解析:在存储过程中设置了需要传参的变量 p_playerno,调用存储过程的时候,通过传参将 57 赋值给 p_playerno,然后进行存储过程里的 SQL 操作。
存储过程体
存储过程体包含了在过程调用时必须执行的语句,例如:dml、ddl 语句,if-then-else 和 while-do 语句、声明变量的 declare 语句等 过程体格式:以 begin 开始,以 end 结束 (可嵌套) BEGIN BEGIN BEGIN statements; END END END 注意:每个嵌套块及其中的每条语句,必须以分号结束,表示过程体结束的 begin-end 块 (又叫做复合语句 compound statement),则不需要分号。
为语句块贴标签:
[begin_label:] BEGIN
[statement_list]
END [end_label]
例如:
label1: BEGIN
label2: BEGIN
label3: BEGIN
statements;
END label3 ;
END label2;
END label1
标签有两个作用:
1、增强代码的可读性 2、在某些语句 (例如: leave 和 iterate 语句),需要用到标签 二、存储过程的参数 MySQL 存储过程的参数用在存储过程的定义,共有三种参数类型, IN,OUT,INOUT, 形式如:
CREATEPROCEDURE 存储过程名 ([[IN |OUT |INOUT] 参数名 数据类形...]) IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量) OUT 输出参数:表示过程向调用者传出值 (可以返回多个值)(传出值只能是变量) INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量) 1、in 输入参数
mysql> delimiter $$
mysql> create procedure in_param(in p_in int)
-> begin
-> select p_in;
-> set p_in=2;
-> select P_in;
-> end$$
mysql> delimiter ;
mysql> set @p_in=1;
mysql> call in_param(@p_in);
+------+
| p_in |
+------+
| 1 |
+------+
+------+
| P_in |
+------+
| 2 |
+------+
mysql> select @p_in;
+-------+
| @p_in |
+-------+
| 1 |
+-------+
以上可以看出,p_in 在存储过程中被修改,但并不影响 @p_id 的值,因为前者为局部变量、后者为全局变量。
2、out 输出参数
mysql> delimiter //
mysql> create procedure out_param(out p_out int)
-> begin
#调用了 inout_param 存储过程,接受了输入的参数,也输出参数,改变了变量 注意:
1、如果过程没有参数,也必须在过程名后面写上小括号例:
CREATE PROCEDURE sp_name ([proc_parameter[,...]]) ……
2、确保参数的名字不等于列的名字,否则在过程体中,参数名被当做列名来处理
建议:
输入值使用 in 参数。 返回值使用 out 参数。 inout 参数就尽量的少用。 三、变量 1. 变量定义 局部变量声明一定要放在存储过程体的开始:
DECLAREvariable_name [,variable_name...] datatype [DEFAULT value]; 其中,datatype 为 MySQL 的数据类型,如: int, float, date,varchar(length)
例如:
DECLARE l_int int unsigned default 4000000;
DECLARE l_numeric number(8,2) DEFAULT 9.95;
DECLARE l_date date DEFAULT '1999-12-31';
DECLARE l_datetime datetime DEFAULT '1999-12-31 23:59:59';
DECLARE l_varchar varchar(255) DEFAULT 'This will not be padded';
- 变量赋值 SET 变量名 = 表达式值 [,variable_name = expression ..]
- 用户变量
在 MySQL 客户端使用用户变量:
mysql > SELECT 'Hello World' into @x;
mysql > SELECT @x;
+-------------+
| @x |
+-------------+
| Hello World |
+-------------+
mysql > SET @y='Goodbye Cruel World';
mysql > SELECT @y;
+---------------------+
| @y |
+---------------------+
| Goodbye Cruel World |
+---------------------+
mysql > SET @z=1+2+3;
mysql > SELECT @z;
+------+
| @z |
+------+
| 6 |
+------+
在存储过程中使用用户变量
mysql > CREATE PROCEDURE GreetWorld( ) SELECT CONCAT(@greeting,' World');
mysql > SET @greeting='Hello';
mysql > CALL GreetWorld( );
+----------------------------+
| CONCAT(@greeting,' World') |
+----------------------------+
| Hello World |
+----------------------------+
在存储过程间传递全局范围的用户变量
mysql> CREATE PROCEDURE p1() SET @last_procedure='p1';
mysql> CREATE PROCEDURE p2() SELECT CONCAT('Last procedure was ',@last_procedure);
mysql> CALL p1( );
mysql> CALL p2( );
+-----------------------------------------------+
| CONCAT('Last procedure was ',@last_proc |
+-----------------------------------------------+
| Last procedure was p1 |
+-----------------------------------------------+
注意:
1、用户变量名一般以 @开头 2、滥用用户变量会导致程序难以理解及管理 四、注释 MySQL 存储过程可使用两种风格的注释
两个横杆 --:该风格一般用于单行注释。
c 风格: 一般用于多行注释。
例如:
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc1 --name存储过程名
-> (IN parameter1 INTEGER)
-> BEGIN
-> DECLARE variable1 CHAR(10);
-> IF parameter1 = 17 THEN
-> SET variable1 = 'birds';
-> ELSE
-> SET variable1 = 'beasts';
-> END IF;
-> INSERT INTO table1 VALUES (variable1);
-> END
-> //
mysql > DELIMITER ;
MySQL 存储过程的调用 用 call 和你过程名以及一个括号,括号里面根据需要,加入参数,参数包括输入参数、输出参数、输入输出参数。具体的调用方法可以参看上面的例子。
MySQL 存储过程的查询 我们像知道一个数据库下面有那些表,我们一般采用 showtables; 进行查看。那么我们要查看某个数据库下面的存储过程,是否也可以采用呢?答案是,我们可以查看某个数据库下面的存储过程,但是是另一钟方式。
我们可以用以下语句进行查询:
selectname from mysql.proc where db='数据库名';
或者
selectroutine_name from information_schema.routines where routine_schema='数据库名';
或者
showprocedure status where db='数据库名';
如果我们想知道,某个存储过程的详细,那我们又该怎么做呢?是不是也可以像操作表一样用 describe 表名进行查看呢?
答案是:我们可以查看存储过程的详细,但是需要用另一种方法:
SHOWCREATE PROCEDURE 数据库. 存储过程名; 就可以查看当前存储过程的详细。
MySQL 存储过程的修改 ALTER PROCEDURE 更改用 CREATE PROCEDURE 建立的预先指定的存储过程,其不会影响相关存储过程或存储功能。
MySQL 存储过程的删除 删除一个存储过程比较简单,和删除表一样:
DROPPROCEDURE 从 MySQL 的表格中删除一个或多个存储过程。
MySQL 存储过程的控制语句 (1). 变量作用域
内部的变量在其作用域范围内享有更高的优先权,当执行到 end。变量时,内部变量消失,此时已经在其作用域外,变量不再可见了,应为在存储过程外再也不能找到这个申明的变量,但是你可以通过 out 参数或者将其值指派给会话变量来保存其值。
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc3()
-> begin
-> declare x1 varchar(5) default 'outer';
-> begin
-> declare x1 varchar(5) default 'inner';
-> select x1;
-> end;
-> select x1;
-> end;
-> //
mysql > DELIMITER ;
(2). 条件语句
if-then-else 语句
mysql > DELIMITER // mysql > CREATE PROCEDURE proc2(IN parameter int) -> begin -> declare var int; -> set var=parameter+1; -> if var=0 then -> insert into t values(17); -> end if; -> if parameter=0 then -> update t set s1=s1+1; -> else -> update t set s1=s1+2; -> end if; -> end; -> // mysql > DELIMITER ;case 语句:
mysql > DELIMITER // mysql > CREATE PROCEDURE proc3 (in parameter int) -> begin -> declare var int; -> set var=parameter+1; -> case var -> when 0 then -> insert into t values(17); -> when 1 then -> insert into t values(18); -> else -> insert into t values(19); -> end case; -> end; -> // mysql > DELIMITER ; case when var=0 then insert into t values(30); when var>0 then when var<0 then else end case
(3). 循环语句
while ···· end while
mysql > DELIMITER // mysql > CREATE PROCEDURE proc4() -> begin -> declare var int; -> set var=0; -> while var<6 do -> insert into t values(var); -> set var=var+1; -> end while; -> end; -> // mysql > DELIMITER ; while 条件 do --循环体 endwhilerepeat···· end repea
它在执行操作后检查结果,而 while 则是执行前进行检查。
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc5 ()
-> begin
-> declare v int;
-> set v=0;
-> repeat
-> insert into t values(v);
-> set v=v+1;
-> until v>=5
-> end repeat;
-> end;
-> //
mysql > DELIMITER ;
repeat
--循环体
until 循环条件
end repeat;
- loop ·····endloop
loop 循环不需要初始条件,这点和 while 循环相似,同时和 repeat 循环一样不需要结束条件, leave 语句的意义是离开循环。
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc6 ()
-> begin
-> declare v int;
-> set v=0;
-> LOOP_LABLE:loop
-> insert into t values(v);
-> set v=v+1;
-> if v >=5 then
-> leave LOOP_LABLE;
-> end if;
-> end loop;
-> end;
-> //
mysql > DELIMITER ;
- LABLES 标号:
标号可以用在 begin repeat while 或者 loop 语句前,语句标号只能在合法的语句前面使用。可以跳出循环,使运行指令达到复合语句的最后一步。
(4). ITERATE 迭代
ITERATE 通过引用复合语句的标号, 来从新开始复合语句:
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc10 ()
-> begin
-> declare v int;
-> set v=0;
-> LOOP_LABLE:loop
-> if v=3 then
-> set v=v+1;
-> ITERATE LOOP_LABLE;
-> end if;
-> insert into t values(v);
-> set v=v+1;
-> if v>=5 then
-> leave LOOP_LABLE;
-> end if;
-> end loop;
-> end;
-> //
mysql > DELIMITER ;
关系代数
关系代数的 9 种操作:
关系代数中包括了:并、交、差、乘、选择、投影、联接、除、自然联接等操作。
考核要求:达到 “简单应用” 层次 知识点:五个基本操作的含义和运算应用
(1) 并 (∪):两个关系需有相同的关系模式,并的对象是元组,由两个关系所有元组构成。 RUS≡{t| t∈R ∨t∈S}
(2) 差 (-):同样,两个关系有相同的模式,R 和 S 的差是由属于 R 但不属于 S 的元组构成的集合。 R-S≡{t| t∈R ∧t 不属于 S}
(3) 笛卡尔积(×):对两个关系 R 和 S 进行操作,产生的关系中元组个数为两个关系中元组个数之积。 R×S≡{t| t=< tr,ts>∧tr∈R∧ts ∈S}
(4) 投影 (σ):对关系进行垂直分割,消去某些列,并重新安排列的顺序。
(5) 选择 (π):根据某些条件关系作水平分割,即选择符合条件的元组。
2.2.2 关系代数的四个组合操作
考核要求:达到 “简单应用” 层次 知识点:四个组合操作的含义和运算应用
(1) 交 (∩):R 和 S 的交是由既属于 R 又属于 S 的元组构成的集合。
(2)联接: 包括θ(算术比较符)联接和 F(公式)联接. 选择 R×S 中满足 iθ(r+j)或 F 条件的元组构成的集合; 概念上比较难理解,关键理解运算实例 等值联接 (θ为等号“=” 的联接)。
(3) 自然联接 (R∞S):在 R×S 中,选择 R 和 S 公共属性值均相等的元组,并去掉 R×S 中重复的公共属性列。 如果两个关系没有公共属性,则自然联接就转化为笛卡尔积。
(4) 除法 (÷):首先除法的结果中元数为两个元数的差,
R÷S 的操作思路如下 ---
R 表中可以满足所有 S 表中对应关系的共键所在 R 表映衬的主键
例:
表 R
| x | y |
|---|---|
| x3 | y1 |
| x3 | y2 |
表 S
| y | z |
|---|---|
| y1 | y1 |
| y2 | y2 |
R÷S=x3
把 S 看作一个块,如果 R 中相同属性集中的元组有相同的块, 且除去此块后留下的相应元组均相同,那么可以得到一条元组, 所有这些元组的集合就是除法的结果
关系代数表达式:
由关系代数运算经有限次复合而成的式子称为关系代数表达式。这种表达式的运算结果仍然是一个关系。可以用关系代数表达式表示对数据库的查询和更新操作。
举例说明:
设教学数据库中有3个关系:
学生关系S(SNO,SNAME,AGE,SEX)
学习关系SC(SNO,CNO,GRADE)
课程关系C(CNO,CNAME,TEACHER)
(1) 检索学习课程号为 C2 的学生学号与成绩
SELECT SNO,GRADE FROM SC
WHERE CNO='C2'
π SNO,GRADE(σCNO='C2'(SC))
(2) 检索学习课程号为 C2 的学生学号与姓名
SELECT SC.SNO,S.SNAME FROM SC,S WHERE SC.SNO=S.SNO
AND SC.CNO='C2'
π SNO,SNAME(σCNO='C2'(S∞SC))
此查询涉及 S 和 SC,先进行自然连接,然后再执行选择投影操作。
π SNO,SNAME(S)∞(πSNO(σCNO='C2'(SC)))
自然连接的右分量为 "学了 C2 课的学生学号的集合"。此表达式比前一个表达式优化,执行起来要省时间、省空间。
(3) 检索选修课程名为 MATHS 的学生学号与姓名
SELECT SC.SNO,S.SNAME FROM SC,S,C WHERE SC.SNO=S.SNO AND SC.CNO=C.CNO
AND C.CNAME='MATHS'
π SNO,SNAME(σCNAME='MATHS'(S∞SC∞C))
π SNO,SANME(σCNAME='MATHS'(S∞SC∞C))
(4) 检索选修课程号为 C2 或 C4 的学生学号
SELECT SNO FROM SC WHERE CNO='C2'
OR CNO='C4'
π SNO(σ CNO='C2'∨CNO='C4'(SC))
(5) 检索至少选修课程号为 C2 或 C4 的学生学号
SELECT SA.SNO FROM SC AS SA,SC AS SB WHERE SA.SNO=SB.SNO AND SA.CNO='C2'
AND SB.CNO='C4'
π 1(σ1=4∧2='C2'∧5='C4'(SC×SC))
(6) 检索不学 C2 课的学生姓名与年龄
SELECT SNAME,AGE FROM S MINUS SELECT S.SNAME,S.AGE FROM SC,S WHERE SC.SNO=S.SNO AND SC.CNO='C2'
(Oracle)
π SNAME,AGE(S)-πSNAME,AGE(σCNO='C2'(ScrossSC))
(7) 检索学习全部课程的学生姓名
这个定义用 SQL 表示比较麻烦,略过
π SNO,CNO(SC)÷πCNO(C) 先用除法取出选取所有课程的 SNO 集 (除法可以理解为一个 Filter) π SNAME(S cross (πSNO,CNO(SC)÷πCNO(C))) 再关联 S 表取出 SNAME
(8) 检索所学课程包含 S3 所学课程的学生学号
这个定义用 SQL 表示比较麻烦,略过
π SNO,CNO(SC)÷ πCNO(σSNO='S3'(SC)) 同样运用了除法的特性
(9) 将新课程元组 ('C10','PHYSICS','YU') 插入到关系 C 中
INSERT INTO C VALUES('C10','PHYSICS','YU')
(C∪('C10','PHYSICS','YU')) 记住该符号的用法
(10) 将学号 S4 选修课程号为 C4 的成绩改为 85 分
UPDATE SC SET GRADE=85 WHERE SNO='S4'
AND CNO='C4'
(SC-('S4','C4',?)∪('S4','C4',85)) 先用 '-' 实现 DELETE 功能,再用 '∪' 实现 INSERT 功能 注意使用? 来表示检索时忽略该字段值
